1000+ Fünf-Sterne-Bewertungen und Top-Auszeichnungen machen uns zu einer der gefragtesten Lernplattformen.

maschke academy blog
Wissen. Technik. Kreativität.
Der offizielle Blog der Maschke Akademie: Updates, Tutorials und Insights aus der Welt der digitalen Bildbearbeitung, KI und visuellen Medien.


Gemini Embedding 2: Ein einheitlicher Ansatz für multimediale KI-Anwendungen
Gemini Embedding 2
ist Googles neues, nativ multimodales Embedding‑Modell, das Text, Bilder, Videos, Audio und Dokumente in einem gemeinsamen Vektorraum abbildet und damit eine einheitliche Basis für sehr unterschiedliche KI‑Anwendungen schafft.
Einheitlicher Embedding‑Raum
- Im Unterschied zu klassischen, meist textbasierten Embeddings kodiert Gemini Embedding 2 fünf Modalitäten (Text, Bild, Video, Audio, PDF) in einem semantischen Raum.
- Eine Textanfrage kann dadurch über denselben Index passende Bilder, Videoclips, Audioausschnitte oder Dokumente finden – mit identischen Ähnlichkeitsmaßen wie etwa Cosine‑Similarity.
Technische Eckdaten
- Text‑Input: bis zu 8192 Tokens Kontext, Unterstützung für über 100 Sprachen.
- Medien: Bilder (mehrere pro Request), Videos bis etwa 2 Minuten, Audio nativ bis rund 80 Sekunden, PDFs bis zu einigen Seiten – jeweils direkt in Embeddings umwandelbar, ohne separate Vorverarbeitung.
- Standard‑Vektoren haben 3072 Dimensionen; mittels „Matryoshka“‑Ansatz lassen sie sich nahezu verlustarm auf kleinere Dimensionen (z.B. 1536 oder 768) reduzieren, um Speicher und Rechenaufwand zu optimieren.
Typische Einsatzszenarien
- Multimodale RAG‑Systeme: Ein gemeinsamer Index für PDFs, Fotos, Screencasts, Audiomitschnitte und Text, der von einem LLM zur Beantwortung von Fragen genutzt wird.
- Semantische Suche & Empfehlung: Per Textprompt passende Medien finden oder von einem Bild aus direkt zu relevanten Texten, Tutorials oder Handbüchern springen.
- Clustering & Analyse großer, gemischter Medienbestände – etwa in Archiven, Forschungssammlungen oder E‑Learning‑Plattformen.
Verfügbarkeit
- Gemini Embedding 2 steht derzeit als öffentliche Vorschau über die Gemini‑API bzw. Vertex AI zur Verfügung und kann dort direkt in eigene Anwendungen und Pipelines eingebunden werden.
Hier findest du weiterführende Informationen: Google Blog
Ähnliche Beiträge

Komplexe Freisteller – Haare und Fell
YouTube
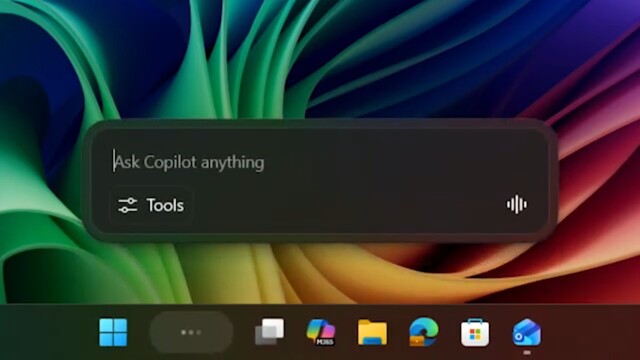
Windows wird zum KI-Betriebssystem:
Agenten in der Taskleiste
Künstliche Intelligenz
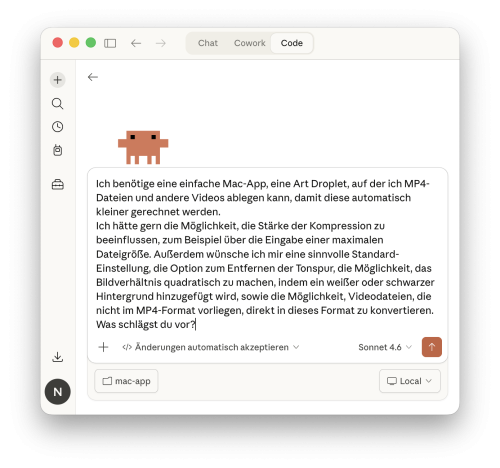
Claude Code im Einsatz: Eigene Mac-Anwendung in Minuten erstellt
Künstliche Intelligenz

Tipp schneller Audioschnitt: Mac-Freeware Ocenaudio mit neuen Funktionen
Technik (Hardware & Software)
Hol’ dir die Weiterbildung im Mail-Format
Starttermine, exklusive Rabatte und spannende Updates direkt in dein Postfach.

