Wissen. Technik. Kreativität.


Die Welt der KI. Was gibt es neues ? Eine Zusammenfassung.
Die Welt der KI
Eine Zusammenfassung von Roland Stand 11.06.2025
ElevenLabs v3: Das steckt hinter ElevenLab 3
ElevenLabs v3 (auch „Eleven v3“ genannt) ist das neueste und bislang ausdrucksstärkste Text-to-Speech-Modell von ElevenLabs, das Anfang Juni 2025 als Alpha-Version veröffentlicht wurde.
Wichtige Neuerungen und Funktionen:
- Ausdrucksstärke & Emotionen: Mit v3 lassen sich Stimmen mit einer bislang unerreichten emotionalen Tiefe erzeugen. Das Modell versteht und interpretiert subtile, im Text eingebettete emotionale Hinweise und kann diese realistisch wiedergeben. Dazu gehören Emotionen wie Flüstern, Seufzen, Lachen oder auch verschiedene Stimmungen wie Freude, Wut oder Traurigkeit.
- Audio Tags: Neu ist ein umfangreiches Tag-System. Mit sogenannten „Audio Tags“ kannst du direkt im Text steuern, wie ein Satz gesprochen werden soll, z.B. [whispers], [shouts], [laughs]. Diese Tags ermöglichen eine sehr feine Kontrolle über Tonfall, Emotion und Timing.
- Dialogmodus: Mit der „Add Speaker“-Funktion kannst du nun echte, natürliche Dialoge zwischen mehreren Stimmen erzeugen. Das Modell erkennt Sprecherwechsel, unterbricht sich gegenseitig und erzeugt so flüssige, authentische Gespräche – ideal für Hörspiele, Podcasts oder Videos.
- 70+ Sprachen: Die Sprachauswahl wurde massiv erweitert – v3 unterstützt jetzt mehr als 70 Sprachen und deckt damit etwa 90 % der Weltbevölkerung ab.
- Einfache Bedienung: Die Einstellungen wurden vereinfacht: Statt vieler Regler gibt es jetzt einen Schieberegler, mit dem du zwischen „Neutral“, „Kreativ“ und „Robust“ wählen kannst. Damit passt du die Ausdrucksstärke der Stimme an deinen Einsatzzweck an.
- Nutzung und Preis: Das Modell läuft aktuell als Alpha mit 80 % Rabatt für Selbstnutzer bis Ende Juni 2025. Die Nutzung ist bereits über die ElevenLabs-Webseite möglich, eine öffentliche API ist in Vorbereitung.
- Einschränkungen: Für Echtzeit- oder Live-Anwendungen empfiehlt ElevenLabs weiterhin die Vorgängerversion (v2.5 Turbo oder Flash), da v3 aktuell noch nicht für Echtzeit optimiert ist.
Typische Anwendungsfälle:
- Hörbücher, Voice-over, Content Creation, Dialoge in Videos, Podcasts, Social Media Clips, Games und vieles mehr.
Fazit:
ElevenLabs v3 hebt KI-Text-to-Speech auf ein neues Level: Mehr Ausdruck, mehr Kontrolle, mehr Sprachen – und besonders für kreative Projekte und realistische Dialoge ein echter Fortschritt.
ElevenLabs V3
V3 ausprobieren: Eleven v3 (alpha) — Das ausdrucksstärkste Text to Speech Modell ElevenLabs Website: https://elevenlabs.io/de
Gemini 2.5 Pro „Goldmane“: Überblick und Funktionen
Gemini 2.5 Pro (Codename „Goldmane“) ist das aktuelle Spitzenmodell der Gemini-KI-Reihe von Google und wurde im Frühjahr 2025 veröffentlicht. Es gilt als deutlicher Fortschritt gegenüber den Vorgängerversionen und richtet sich an professionelle Nutzer, Unternehmen sowie Kreative.
Wichtige Neuerungen und Eigenschaften:
- Deutlich verbesserte Genauigkeit: Im Vergleich zu früheren Versionen hat Gemini 2.5 Pro die Fehlerquote bei Benchmarks wie Aider Polygot drastisch reduziert. Das Modell erreicht laut aktuellen Tests eine Genauigkeit von 86,2 %, was einen Sprung von über 13 Prozentpunkten gegenüber dem Vorgänger bedeutet. Damit werden etwa halb so viele Fehler gemacht wie zuvor – ein großer Fortschritt für anspruchsvolle Aufgaben wie Programmierung und Recherche.
- Multimodale Fähigkeiten: Gemini 2.5 Pro kann nicht nur Text, sondern auch Audio, Bilder und Videos verarbeiten. Das Modell eignet sich somit für vielseitige Anwendungsfälle wie Inhaltsanalyse, Zusammenfassungen, Social-Media-Content und sogar App-Entwicklung ohne Programmierkenntnisse.
- Deep Research: Mit dem „Deep Research“-Feature lassen sich besonders gründliche, quellenbasierte Recherchen durchführen. Die Antworten sind umfangreich, gut belegt und für komplexe Wissensfragen geeignet – allerdings kann die Bearbeitung bis zu zehn Minuten dauern.
- Schnelle und präzise Antworten: Für einfache Fragen oder schnelle Auskünfte gibt es die Variante „Gemini 2.5 Flash“, die besonders kurze Antwortzeiten bietet, dabei aber weniger tiefgehend ist.
- Automatisierte Content-Erstellung: Gemini 2.5 Pro kann lange Meetings oder Videos automatisch zusammenfassen, Social-Media-Posts generieren, YouTube-Shorts-Skripte erstellen und sogar interaktive Apps und Tools bauen – alles ohne Programmieraufwand.
- Praktische Integration: Das Modell ist über Google AI Studio und Gemini Advanced verfügbar und lässt sich in bestehende Workflows integrieren.
Einschätzung und Kritik:
- Gemini 2.5 Pro wird als großer Schritt nach vorne bewertet, vor allem bei Genauigkeit und Funktionsumfang. Die Halluzinationsrate ist gesunken, aber nicht vollständig beseitigt – bei Unsicherheiten kann das Modell weiterhin ungenaue Aussagen machen.
- Das Premium-Abo für Gemini Advanced kostet 21,99 Euro pro Monat und wird von einigen Nutzern als teuer empfunden.
- Die Integration in Smart-Home-Geräte und Wearables ist noch nicht vollständig abgeschlossen; hier gibt es weiterhin Einschränkungen.
Fazit:
Gemini 2.5 Pro „Goldmane“ ist ein leistungsstarkes, vielseitiges KI-Modell mit deutlichen Verbesserungen bei Genauigkeit, Multimodalität und Automatisierung. Besonders für professionelle Anwendungen, Content-Erstellung und tiefgehende Recherchen ist es ein echter Fortschritt – auch wenn der Preis und die Integration in den Google-Kosmos noch nicht für alle Nutzer optimal sind.
Gemini 2.5 Pro „Goldmane“
Ankündigung: https://blog.google/products/gemini/gemini-2-5-pro-latest-preview/
Luma Modify Video: KI-gestützte Videobearbeitung auf neuem Level
Luma Modify Video ist ein innovatives KI-Tool von Luma Labs, das es ermöglicht, bestehende Videos umfassend zu verändern – von subtilen Anpassungen bis hin zu kompletten Neugestaltungen. Das Besondere: Die originale Bewegung, Mimik und Kameradynamik bleiben erhalten, während Stil, Umgebung oder einzelne Elemente nach Wunsch angepasst werden können.
Kernfunktionen und Möglichkeiten:
- Komplette Umgestaltung ohne Nachdrehs: Du kannst das Setting, den Stil oder sogar ganze Charaktere verändern, ohne das Video neu zu drehen oder aufwändig zu animieren. So wird aus einer Alltagsszene eine Fantasy-Welt, ein Outfit-Wechsel oder eine neue Lichtstimmung – alles KI-gesteuert und ohne Greenscreen.
- Präzise Steuerung: Die KI erkennt und erhält Bewegungen, Gesichtsausdrücke und die Struktur der Szene. Änderungen lassen sich per Textprompt, Referenzbild oder durch Auswahl eines Einzelbilds steuern. Die Bedienung ist dabei so einfach wie ein Gespräch mit einem Cutter.
- Drei Bearbeitungsmodi:
- Adhere: Für subtile Anpassungen wie Texturen oder Licht, sehr nah am Original.
- Flex: Für spürbare Stiländerungen bei Erhalt der wichtigsten Elemente.
- Reimagine: Für maximale kreative Freiheit, z.B. Verwandlung von Menschen in Fantasiewesen oder komplette Szenenwechsel.
- Elemente gezielt bearbeiten: Kleidung, Requisiten, Hintergründe oder Effekte lassen sich separat verändern, ohne den Rest des Videos zu beeinflussen. Auch komplexe Aufgaben wie das Altern von Figuren oder das Austauschen von Objekten sind möglich – ohne Maskierung oder Frame-by-Frame-Arbeit.
- Motion & Performance Transfer: Bewegungen, Choreografien oder Mimik aus beliebigen Videos lassen sich extrahieren und auf andere Szenen oder Charaktere übertragen.
- Textbasierte Bedienung: Beschreibe einfach, was Du verändern möchtest – die KI setzt es visuell um. Beispiele: „Gib dem Video einen Anime-Look“, „Mache die Szene neblig und kühler“, „Tausche das rote Auto gegen ein blaues Fahrrad“.
- Schnelle Ergebnisse: Was früher Tage an VFX-Arbeit bedeutete, ist jetzt in Minuten erledigt – inklusive Export und Weiterbearbeitung.
- Technische Details: Unterstützt Videos bis zu 10 Sekunden, idealerweise mit stabiler Kamera und sauberem Hintergrund für beste Resultate. Die Bearbeitung läuft aktuell über das Web mit Dream Machine-Abo, iOS folgt bald.
Fazit:
Luma Modify Video hebt KI-Videobearbeitung auf ein neues Level: Du kannst Deine kreative Vision in Worte fassen – die KI setzt sie um, ohne die Dynamik und Qualität des Originals zu verlieren. Das Tool eignet sich für Fotografen, Filmemacher, Content Creator und alle, die Videos flexibel und professionell transformieren möchten.
Luma Modify Video
Luma Website: https://lumalabs.ai
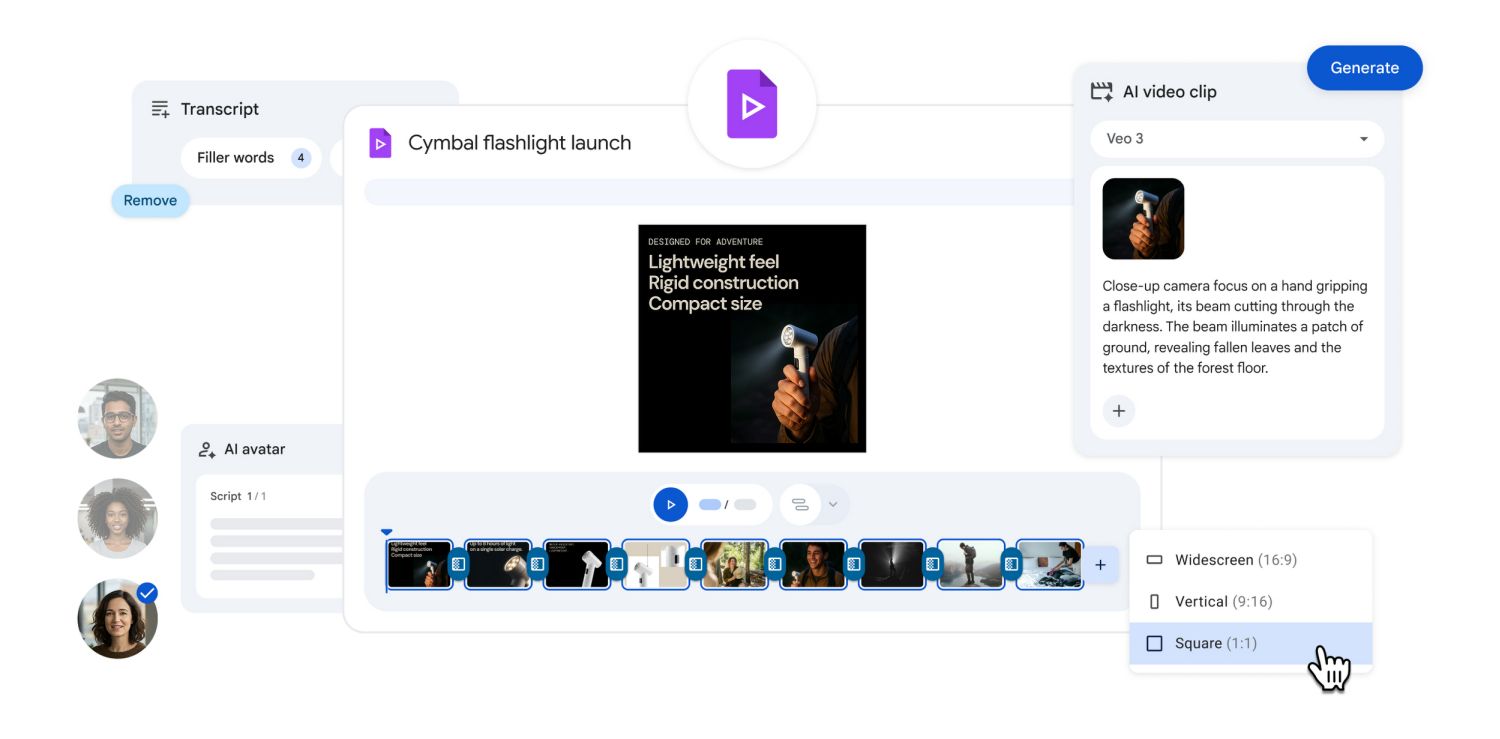
Veo 3 Fast: Das neue Turbo-Upgrade für Googles KI-Videogenerator
Veo 3 Fast ist die beschleunigte Version von Googles KI-Videomodell Veo 3 und wurde im Juni 2025 vorgestellt. Ziel ist es, die Erstellung von KI-generierten Videos deutlich schneller und günstiger zu machen – bei gleichbleibender Qualität.
Die wichtigsten Fakten zu Veo 3 Fast:
- Mehr als doppelt so schnell: Veo 3 Fast generiert Videos mehr als doppelt so schnell wie die Standardversion von Veo 3. Die typische Generierungszeit für einen 8-Sekunden-Clip sinkt um etwa 30 %, sodass Ideen und Konzepte nahezu in Echtzeit getestet werden können.
- Gleiche Qualität: Die Videoauflösung bleibt bei 720p, es gibt keine Einbußen bei der visuellen Qualität oder beim Audio.
- Native Audio-Integration: Veo 3 Fast erzeugt Videos mit synchronisiertem Ton – inklusive Dialog, Umgebungsgeräuschen und Soundeffekten. Damit entfällt aufwändiges Nachvertonen oder Lip-Sync.
- Deutlich günstiger: Ein Video im Fast-Modus kostet nur 20 Credits (statt 150 im Standardmodus) – das entspricht einer Kostenersparnis von 80 %. Nutzer können im Ultra-Plan bis zu 625 Clips pro Monat generieren.
- Für wen ist Veo 3 Fast gedacht? Ideal für Kreative, Marketer, Lehrende und alle, die viele Ideen schnell testen oder Prototypen mit Ton und Bild erstellen möchten.
- Zugang & Nutzung: Veo 3 Fast ist in den USA bereits über die Gemini App und die Filmmaking-Plattform Flow verfügbar. Gemini Pro-Nutzer erhalten drei Fast-Generierungen pro Tag, Flow Pro-Nutzer zahlen 20 Credits pro Video. In Europa und Deutschland ist Veo 3 Fast noch nicht verfügbar, Google arbeitet jedoch an einer Lösung.
- Funktionsumfang: Aktuell wird Text-zu-Video unterstützt, Bild-zu-Video ist in Entwicklung. Die KI kann künstlerische Stile, Charakterdesigns und Kameraführung konsistent umsetzen. Für höchste Produktionsqualität (4K, komplexe Physik) empfiehlt sich weiterhin der Standardmodus.
Fazit:
Veo 3 Fast macht Googles KI-Videogenerierung massentauglich: schneller, günstiger, mit nativer Audioausgabe und ideal für schnelle Iterationen. Für professionelle Endproduktionen bleibt der Standardmodus relevant, aber für Prototyping, Storyboarding und kreative Experimente ist Veo 3 Fast ein echter Gamechanger. In Europa heißt es noch abwarten – der Start wird aber erwartet.
Veo 3 Fast
Beispiele: https://x.com/fofrAI/status/1931472803053576659
Cursor Version 1.0: Die wichtigsten Neuerungen
Cursor 1.0 ist die erste stabile Hauptversion des KI-Codeeditors Cursor und bringt zahlreiche neue Funktionen und Verbesserungen.
Hauptfeatures von Cursor 1.0:
- BugBot für automatischen Code-Review:
BugBot prüft automatisch Pull Requests (PRs) auf Fehler und Probleme. Bei gefundenen Fehlern hinterlässt BugBot Kommentare direkt im PR, sodass du schnell reagieren und die Korrektur im Editor starten kannst. - Background Agent für alle Nutzer:
Der Background Agent ist ein KI-gesteuerter, ferngesteuerter Coding-Agent, der Code in einer Remote-Umgebung bearbeiten kann. Er kann ein GitHub-Repository klonen, auf einem eigenen Branch arbeiten und Änderungen pushen. Die Funktion ist jetzt für alle Nutzer verfügbar. - Jupyter-Notebook-Unterstützung:
Cursor kann jetzt direkt Änderungen in Jupyter Notebooks vornehmen und mehrere Zellen automatisch erstellen oder bearbeiten. Dies ist besonders für Data Science und Forschung nützlich. - Memories (Beta):
Mit „Memories“ kann sich Cursor projektbezogen Fakten und Anweisungen aus bisherigen Chats merken und diese später wieder nutzen. Die Verwaltung erfolgt in den Einstellungen. - MCP-One-Click-Install und OAuth:
MCP-Server (Model Context Protocol) lassen sich jetzt mit einem Klick in Cursor integrieren. Die Authentifizierung über OAuth wird unterstützt, was die Anbindung externer Tools wie GitHub, Figma, Notion, Stripe und Playwright erleichtert. - Richer Chat Responses:
Cursor kann jetzt Visualisierungen wie Mermaid-Diagramme und Markdown-Tabellen direkt im Chat anzeigen. - Neues Dashboard und Einstellungen:
Das Dashboard wurde überarbeitet. Es zeigt jetzt Nutzungsstatistiken für Einzelpersonen und Teams, ermöglicht das Ändern des Anzeigenamens und bietet detaillierte Auswertungen nach Tool oder Modell. - Weitere Verbesserungen:
Sicherheitshinweis:
Der Background Agent hat umfassende Zugriffsrechte auf Repositories und kann automatisiert Befehle ausführen. Damit steigt das Risiko für Angriffe wie Prompt Injection. Die Infrastruktur wurde bisher noch nicht von Dritten auditiert.
Fazit:
Cursor 1.0 ist ein mächtiger KI-Codeeditor, der mit BugBot, Background Agent, Jupyter-Support, Memories und vielen weiteren Features einen großen Schritt in Richtung automatisierte und intelligente Softwareentwicklung macht.
Cursor Version 1.0
Cursor Website: https://www.cursor.com
Open Source Deep Research: Überblick und aktuelle Projekte
Was ist Deep Research? Deep Research bezeichnet eine neue Generation von KI-gestützten Recherche-Agenten, die komplexe, mehrstufige Fragestellungen durch strukturierte Websuche, Analyse und Synthese von Informationen beantworten. Im Gegensatz zur klassischen Suche liefern diese Systeme keine Linklisten, sondern ausführliche, zitierte Berichte und Analysen.
Wichtige Open-Source-Projekte und Frameworks
1. Together AI – Open Deep Research
- Together AI hat mit „Open Deep Research“ ein quelloffenes KI-Tool veröffentlicht, das komplexe Fragen in vier Schritten bearbeitet: Planung der Suchanfragen, Sammeln von Inhalten, Lückenanalyse und Verfassen eines strukturierten Berichts.
- Die Architektur kombiniert spezialisierte Open-Source-Modelle (z.B. Qwen2.5, Llama-3, DeepSeek-V3) und ist vollständig offen für die Community.
- Ziel ist, nicht nur kurze Antworten, sondern umfassende, gut belegte Reports zu liefern – ähnlich wie OpenAI Deep Research, aber mit offenem Code, eigenen Datensätzen und frei wählbarer Infrastruktur.
2. Deep-Research (dzhng)
- Ein iterativer Recherche-Agent, der Suchanfragen generiert, Webseiten durchsucht und die Inhalte mit einem Reasoning-Modell (z.B. o3-mini) verarbeitet.
- Vollständig Open Source, flexibel anpassbar und für eigene Workflows nutzbar.
3. OpenDeepResearcher
- Asynchroner KI-Agent, der mit mehreren Suchmaschinen und Content-Extraktoren arbeitet und verschiedene Open-Source-LLMs für die Analyse nutzt.
- Ermöglicht detaillierte, iterative Recherchen und kann individuell erweitert werden.
4. Open Deep Research by Firecrawl
- Ein leichtgewichtiges Framework, das Firecrawl für Suche und Extraktion nutzt und beliebige LLMs für die eigentliche Analyse einbindet.
- Besonders geeignet für Selbst-Hosting und individuelle Anpassungen.
5. DeepResearch von Jina AI
- Repliziert den Workflow von OpenAI Deep Research mit Integration verschiedener Suchmaschinen und fortschrittlicher KI-Modelle.
- Starke Fokussierung auf Kontextverständnis, Extraktion und Zusammenfassung relevanter Inhalte.
Technische Prinzipien und Trends
- Agentic Frameworks: Open-Source-Deep-Research-Projekte setzen auf Agenten, die LLMs mit Tool-Use (z.B. Websuche, PDF-Analyse) kombinieren und ihre Aktionen in Schritten organisieren. Dadurch lassen sich komplexe Rechercheaufgaben automatisieren und die Leistungsfähigkeit der LLMs gezielt erweitern.
- Modularität: Die meisten Open-Source-Lösungen sind modular aufgebaut, sodass verschiedene Modelle, Datenquellen und Extraktionsmethoden flexibel kombiniert werden können.
- Multimodalität: Neue Frameworks unterstützen zunehmend auch die Verarbeitung von Bildern, PDFs, Audio und Video, nicht mehr nur Text.
- Lokale Ausführung: Viele Projekte können komplett lokal laufen, was Datenschutz und Anpassbarkeit erhöht.
Fazit
Open Source Deep Research ist ein dynamisch wachsendes Feld: Es gibt bereits mehrere leistungsfähige, frei verfügbare Alternativen zu proprietären Systemen wie OpenAI Deep Research. Sie ermöglichen automatisierte, mehrstufige Rechercheprozesse mit ausführlichen, belegten Berichten – und lassen sich flexibel an eigene Anforderungen anpassen. Besonders hervorzuheben sind Together AI Open Deep Research, Deep-Research, OpenDeepResearcher, Firecrawl und Jina AI DeepResearch. Die Entwicklung geht rasant weiter, mit Fokus auf Flexibilität, Multimodalität und Selbst-Hosting.
Open Source Deep Research
Github: https://github.com/google-gemini/gemini-fullstack-langgraph-quickstart
Bing Video: Kostenloser KI-Video-Generator von Microsoft
Bing Video Creator ist ein neues, kostenloses KI-Tool von Microsoft, das es ermöglicht, aus einfachen Texteingaben kurze Videos zu generieren. Die Funktion basiert auf OpenAI Sora und ist seit Juni 2025 zunächst in der Bing-App für iOS und Android verfügbar.
Wichtige Funktionen und Eigenschaften:
- Text-zu-Video: Nutzer geben eine Beschreibung ein, und die KI erstellt daraus ein kurzes Video. Zum Beispiel: „In einer belebten italienischen Pizzeria arbeitet ein Otter als Koch.“
- Länge und Format: Die Videos sind aktuell 5 Sekunden lang und werden im Hochformat (9:16) generiert. Ein Querformat (16:9) ist in Vorbereitung.
- Einfache Bedienung: Die Funktion ist direkt in der Bing-App unter „Video Creator“ zu finden oder kann über die Suchleiste mit einem Prompt wie „Create a video of...“ genutzt werden.
- Kostenlos: Die ersten zehn schnellen Video-Generierungen sind gratis. Danach kann man mit Microsoft Rewards-Punkten weitere schnelle Generierungen freischalten oder auf den Standardmodus umsteigen.
- Benachrichtigung und Download: Nach Fertigstellung erhält man eine Benachrichtigung, kann das Video herunterladen, teilen oder einen Link generieren. Die Videos bleiben 90 Tage gespeichert.
- Drei Videos gleichzeitig: Es lassen sich bis zu drei Videos gleichzeitig in die Warteschlange stellen.
- Zielgruppe: Besonders geeignet für Content Creator, Social-Media-Posts, Marketing, Bildung und alle, die schnell visuelle Ideen umsetzen wollen.
- Desktop-Version: Eine Version für den Desktop und die Integration in Copilot Search sind angekündigt und folgen in Kürze.
Fazit:
Bing Video Creator macht KI-Videoerstellung für alle zugänglich – kostenlos, einfach und direkt über die Bing-App. Die kurze Videolänge und intuitive Bedienung eignen sich besonders für schnelle, kreative Clips für Social Media und Marketing. Die Integration von Sora hebt die Qualität auf ein neues Level und bietet erstmals kostenlose Video-KI für die breite Öffentlichkeit.
Bing Video
Ankündigung: https://blogs.bing.com/search/June-2025/Introducing-Bing-Video-Creator?form=M30190&OCID=M30190
Ähnliche Beiträge